前阵子做搜索分词,测试环境一切正常, 切换到运营,发现无法建索引了,层层定位原来是Mysql数据源的问题。 没过多久 客户端的小伙伴们也遇到了Mysql返回 '???'。深感大家都是做大事的人,怎么能老被编码这个东西坑住呢。
ASCII 没啥好说的 0x00 – 0x7f 地球人都会查表
Unicode码 其实这不能叫码,应该叫Unicode表 老祖宗啊
Latin-1解决了欧洲字符集编码的问题,还有亚洲的中文,日文,韩文及非洲的语言,你西方人用Latin- 1 , 1个字节拉丁语,英语够了不会管别人的。 别的民族只能自己扩展编码 于是出现了GBK GB2312 BIG5等。 最终实在太混乱了! 国际组织建立了Unicode编码,用于对世界上所有的语言进行编码。记住在Unicode字符表中,每种语言的每个文字都占了一个坑 。Unicode编码由两个字节(常用够了)或四个字节(甲骨文之类)来表示。
这里看到在没有互联网之前 大家都在各自的国家地区用自己的编码字符集挺好了,但一切都在出现了互联网之后,各种乱码 无法解释的编码 Unicode字符集就重要起来。
UTF8编码 Unicode表的一种落地实现 (包括传输<大小端>,字节存储,解释等)
Unicode 一切都2字节,很让西方人感到不爽,为了解决Unicode用于表示ASCII码的效率非常的低,要比ASCII编码多出一倍空间的问题。 就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Universal Transformation Format)。
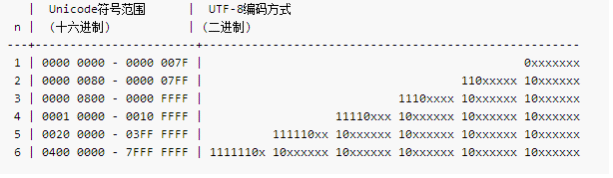
Unicode 转换为 UT8后的范围是 1-- 6 个字节, 西方人的都是1字节,中国人3字节,少数的字4 -- 6字节。 但这也会让中国人不爽,我明明没有Unicode的时候GBK 2个字节就够了,你非要统一让我用3字节,所以现在双方共存。补充一下, UTF8 解释Unicode的时候单位是1个字节 ,所以没有字节序困扰。 UTF16 的落地实现涉及到了 大小端对齐, 因为它需要两个字节为单位的Unicode解释, 用 BOM 来记录对其方式等。
记住 : GBK 如果想转换成UTF8 , 是没有二进制规律的,一般都是通过
GBK 查表 --à Unicode对应坑 -à 按照规则变成- : UTF8 。
所以java世界里面聪明的用了Unicode 为基准,支持Unicode 4.0 。 这样你写
Char a = ‘露’ char b = ‘L’ 都是可以的。因为 java 一个Char 两个字节 而 ‘L’ 和 ‘露’ 都是2个字节就可以表示的Unicode (基平面2字节) 。如果你要表示复杂的文字(扩展平面4字节) 就要用Char数组了。 其实Windows也是, 你复制一段文字,其实是在内存中保持成了Unicode ,然后在粘贴到别的应用中按照他的编码显示。
重点 (请记住):
UNICODE到UTF-8的转换就是
1 先确定编码所需要的UTF-8编码字节数
2 然后用UNICODE编码位从低位到高位依次按规则填入空位,不足的高位以0补充
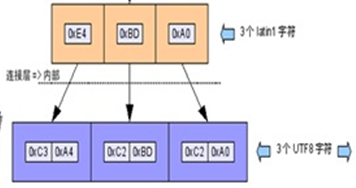
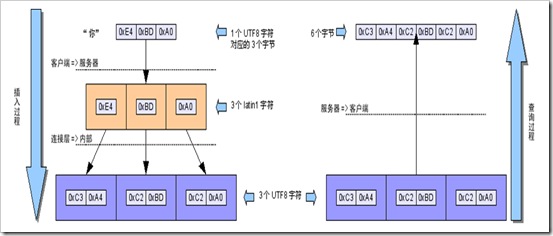
这里先剧透露一下,为什么 Mysql 可以指定编码为 Latin-1 还能保持中文, 他明明就1个字节啊。事情其实是个样子:英语就不说了,别的文字,不管你需要用几个文字,你总要用字节,一个字节一个字节的传输,存储吧 。 得 ,那我就把 这一个一个的字节 叫Latin-1吧, 反正你都是 0x00 – 0xff 的字节范围。 比如 ‘你’ 的 UTF8编码是

那我就把它当成 3个 Latin1 好了(0xE4 ,0xBD,0xA0)。 存储到Mysql里面 ,然后取的时候 你也Laint1取走。 页面自己解释回 UTF8。世界多美好啊。但是! 只要有人中途岔了一脚别的编码 ,你可能就死定了, 下面会详细说。
哦 等等, 这里推荐两个武器。 后面会用到它们。
http://rishida.net/tools/conversion/ Unicde 与转换任何字符集的相互转换。
http://bm.kdd.cc/index.asp 专门转中文GBK BIG5之类用的
1 Mysql字符集变量
我们知道Mysql 一共有下面几个和字符集有关的变量:

这里抓住造成 乱码 或者 ’???’ 的主要矛盾 ,我们先来看红色标注的变量。
先简单解释这几个变量
character_set_client: 客户端来源数据使用的字符集
客户端显示告诉服务器所发送来的语句中的字符集编码
character_set_connection: 连接层字符 (最重要!)
mysql使用character_set_connection字符集,将客户端的字符串,转换为character_set_connection 表示的字符集
character_set_results: 查询结果字符集
mysql将数据存储的字符集转换成character_set_results返回给前端
character_set_database: 当前选中数据库的默认字符集
create table没有指定字符集时候默认的字符集。记住Mysql可以指定:
字段字符集à表字符集à数据库字符集à服务器字符集 (从大到小,下级服从上级)
character_set_server: 默认的内部操作字符集 (基本可以忽略)
创建一个新的数据库时,除非明确指定,这个数据库的字符集被缺省设定
character_set_system: 系统元数据(字段名等)存储的时候使用字符集 (更忽略)
为什么说这3个红色的最重要呢, 因为写php的同学都知道,当发生乱码了 ,在php访问mysql前面加上
mysql_query("SET NAMES GBk");
世界有时候就干净了, 有时候也不 :),其实 Set names gbk 等价于
set character_set_client =gbk;
set character_set_connection = gbk;
set character_set_results = gbk;
先粗略介绍一下Mysql是怎么做字符转换的。
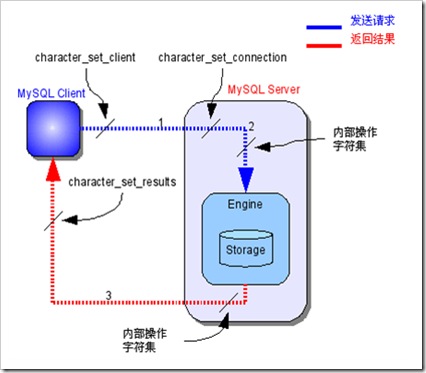
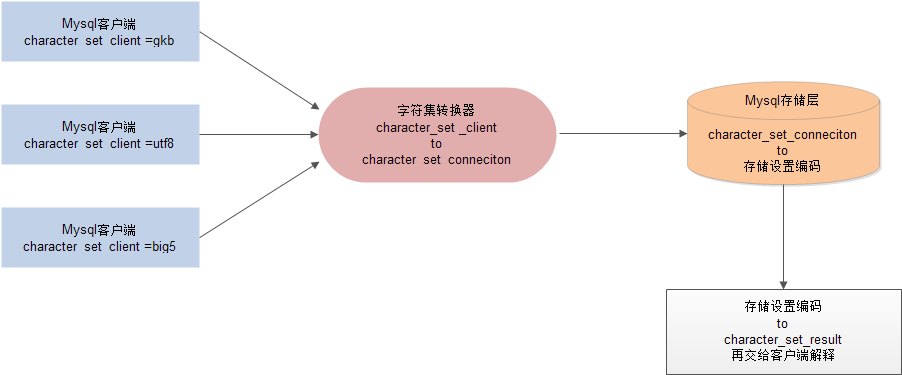
1 MySQL Server收到请求时将请求数据从
character_set_client转换为character_set_connection;
2 进行内部操作前将请求数据从character_set_connection转换为内部操作字符集,其确定方法如下:
• 使用每个数据字段的CHARACTER SET设定值;
• 若上述值不存在,则使用对应数据表的DEFAULT CHARACTER SET设定值
• 若上述值不存在,则使用character_set_server设定值。就是刚才上下级的关系。
3. 将操作结果从内部操作字符集转换为character_set_results返回。
3 Mysql 定位乱码的步骤 重点
这个你要么去看mysql的存储引擎文件,如果你想知道怎么看 请RTX我,我会给你指条明路的 :)。更实际的办法是 用hex (select hex(字段名) from table)函数,和我刚才贴的那个工具网址
现在这里有一张g 表; 我们看到表的编码是 gbk

如果 你 将返回结果设置为 latin1 或者 gdk 然后再做查询。
mysql> set character_set_results = latin1;
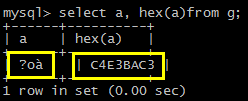
就会看到 select 字段a 返回的是乱码,hex(a) 则是存储的内容:
这就比较郁闷了
为什么字段a 显示 不对。 此时你就需要知道 hex(a) 到底是什么编码。 如果你看多了,基本可以看出来是黄色框框的3字节是一个UTF8汉字...
一般的情况是 你知道自己前端插入的是什么,用刚才网址转换一下看看,存的是不是这个编码的字。

很明显 C4E3 ,是gbk ,而不是utf8 。存储是没有问题的,刚刚我们
mysql> set character_set_results = latin1 or gbk;
会不会这个有关呢,想想这是返回给shell终端的编码,它已经不是Mysql存储的编码了,而是被转换成了character_set_results的编码交给shell解释,
这个时候看一下你解释编码的那个程序 可能是浏览器 可能是客户端
比如我用的是 SecureCRT 它如果解释错了,还是一场空。

这个时候 你想能正常显示就需要
1mysql> set character_set_results = utf8;
2更改终端编码设置使得能够解释显示
PS : 你可以通过 mysql 的convert 函数,把表中记录修改成 UTF8 编码;
如果你hex的结构是 一连串的 3F, 那么恭喜你,你可以安息了,因为你的数据已经丢失了,原因马上讲,记得这可能在你表是 Latin1或者character_set_connection =latin1 的时候发生。
说的通俗一点,在 Mysql中的转换过程中当:
1 你把一个任何编码转换,存储成 Latin1的时候发生丢失(不可修复) 见 4.case2
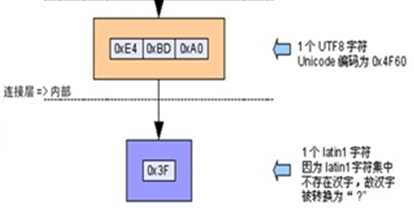
为什么? 记得剧透里面说过,你只能把 UTF8 一个一个的变成 Latin1, 但不能转换,
因为根本没有规则, UTF8字符对应的 Unicode范围根本不在Latin1内, 只能变成0x3F。
2 在你把Latin1转换或者存储成任何一种编码的时候(勉强可以修复) 见4.case1
Latin1 是不能转换成 UTF8的,它会先变成 Unicode 然后在根据 Uincode转换UTF8的规则,一个字节一个字节的转,基本情况就是 (你可以用刚才贴的网址工具验证)
Latin1 害死人,如果你不想纠结了 你记住下一个黄金法则
如果一路上 (mysql 表属性 ,client ,connection, result ) 中有一个是Latin1, 强烈建议都是Latin1,这样世界比较清静! 编码解释的工作交给客户端来就行了。
1 检查 character_set_client 是否和你真正 资源文件中的编码一致;
比如你是 java 你一定有一个system.resource 的各种编码文件
C 也一定有一个 xxx_gbk.h xxx_utf8.h 之类的定义,他们是啥,你character_set_client就要是啥, Mysql client 会帮你用这个来转换,一旦文件是utf8 但character_set_client = gbk8 这个时候字符可能已经被截断了, utf8 是3字节的 ,你会看到只保留了前2字节,然后在解释,就是各种乱码 , 这个时候你也回不去了!
这个时候的黄金法则是所有你的客户端: set names = xxx
当然你无法保证你不是一个公开的服务,客户端各种实现,五花八门,所以这个时候就有了 character_set_connection
MysqlServer会把一切客户端过来的连接,
character_set_client 变成 character_set_connection
这个时候只要客户端过来的编码没问题,就会通过系统的字符转换函数(gconv) 统一变成
character_set_connection的字符集,然后再变成表设置的编码,落地。
这段内容部分来自于网络,我也找不到原作者了,表示谢意
向默认字符集为utf8的数据表插入utf8编码的数据前没有设置连接字符集,查询时设置连接字符集为utf8
– 插入时根据MySQL服务器的默认设置
character_set_client = latin1
character_set_connection = latin1
character_set_results = latin1;
– 插入操作的数据将经过latin1=>latin1=>utf8的字符集转换过程,这一过程中每个插入的汉字都会从原始的3个字节变成6个字节保存;
– 查询时的结果将经过utf8=>utf8的字符集转换过程,将保存的6个字节原封不动返回,产生乱码……
向默认字符集为latin1的数据表插入utf8编码的数据前设置了连接字符集为utf8
– 插入时根据连接字符集设置,
character_set_client = utf8;
character_set_connection = utf8;
character_set_results = utf8;
– 插入数据将经过utf8=>utf8=>latin1的字符集转换,若原始数据中含有/u0000~/u00ff范围以外的Unicode字符,会因为无法在latin1字符集中表示而被转换为“?”(0x3F)符号,以后查询时不管连接字符集设置如何都无法恢复其内容了。

• 建立数据库/表和进行数据库操作时尽量显式指出使用的字符集,而不是依赖于MySQL的默认设置,否则MySQL升级时可能带来很大困扰;
• 数据库和连接字符集都使用latin1时虽然大部分情况下都可以解决乱码问题,但缺点是无法以字符为单位来进行SQL操作,一般情况下将数据库和连接字符集都置为utf8是较好的选择;
• 使用mysql C API时,初始化数据库句柄后马上用mysql_options设定MYSQL_SET_CHARSET_NAME属性为utf8,这样就不用显式地用SET NAMES语句指定连接字符集,且用mysql_ping重连断开的长连接时也会把连接字符集重置为utf8;
下面一段是网上搜的,误人子弟太多,唉
• character_set_client和character_set_results 一般情况下要一致,因为一个表示客户端发送的数据格式,另一个表示客户端接受的数据格式为了避免造成数据丢失,需让 character_set_connection的字符编码 大于 character_set_client的字符编码
好了, 先说这么多, 希望大家多改改
这些变量的不同组合,找出乱码的情况
然后自己用 hex() 配合贴的网址做实验, 就更清晰了!
补充 (这部分可以跳过)
可能有做前端的同事会看到这个 js 匹配中文的正则

第一句话为什么正确呢。 因为常见的中文确实在UNICODE+4e00 –UNICODE+9fa5之间。
那为什么页面其实有自己的编码 但是用 Unicode也可以匹配呢,前提是你已经转成了Unicode 。 这里不详细讲传送门:http://blog.csdn.net/yimengqiannian/article/details/7016720
有的时候我们用mysql_real_escape_string的时候,会发现有的中文或者字符后面多了 ‘\’ 这是为什么呢,这是经典的 0x5c问题,因为在gbk 中,有的中文 最后一个字节是0x5c,这样mysql会认为是asc ‘\’ 而做了转义增加了’\’ ,但这其实是一个误判, 我们需要告诉mysql这个是一个gbk ,两字节宽度的中文 ,而告诉的方式就是。mysql_set_charset("gbk")。