在QT娱乐项目中,因为整个项目充斥着一些重要的数据,并且在使用中需要对这些数据进行一些常规的关系型检索,因此我们自然而然会选择使用mysql来存储这些数据。但是在使用mysql的过程中,常常会遇到mysql的DB机器CPU飙到100%的情况,问题的原因文章的标题已经提到,大部分原因是因为在查询中没有命中索引而查询全表导致的。
下面以实际运营过程中遇到的问题来说明索引的重要性,以艺人上直播发送tips为例。订阅关注DB的CPU曲线如下图所示:
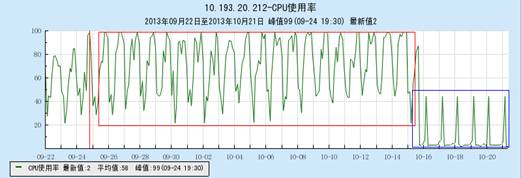
由上图红色框中所示,在优化前该DB在高峰期的CPU一直都是在100%。
在订阅关系中,我们只存了用户到艺人的映射关系,也就是说以用户分表,每张表结构类似如下图所示:
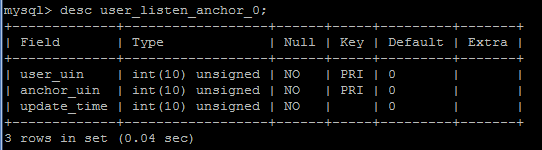
建表sql类似如下:
create table if not exists user_listen_anchor_0 (user_uin int unsigned not null default 0, anchor_uin int unsigned not null default 0, update_time int unsigned not null default 0, primary key(user_uin, anchor_uin)) engine=innodb default charset=utf8;
因为user_uin和anchor_uin是主键,所以这两个字段本身就是一种唯一性索引,我们可以看下这张表的索引:
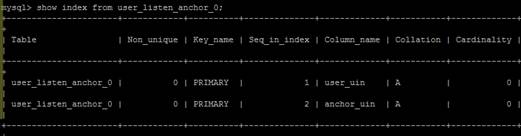
从图中可以看出这张表确实建立了索引,但是实际上你可以把这个索引理解为组合索引,而对于(user_uin, anchor_uin)这个组合索引而言,mysql只能用到其中的那个它认为似乎是最有效率的单列索引,建立这样的索引,其实是相当于分别建立了下面两组索引:
1、user_uin, anchor_uin
2、user_uin
对,没有anchor_uin的索引,我们可以通过explain来帮助我们验证这个结果。
(1)执行 explain select update_time from user_listen_anchor_0 where user_uin=0 and anchor_uin=0; 结果如下图:

explain结果中可以看出当where条件为user_uin+anchor_uin时,连接的type为const,并且命中主键索引,所以这种查询sql是会命中索引的,而且速度会很快,因为type是const,mysql只会读取一次。
(2)执行 explain select update_time from user_listen_anchor_0 where user_uin=0; 结果如下图:

explain结果中可以看出当where条件为user_uin时,也会命中主键索引,所以这种查询sql速度也是可以的。
(3)执行 explain select update_time from user_listen_anchor_0 where anchor_uin=0; 结果如下图:

explain结果中可以看出当where条件为anchor_uin时,连接的type为all,表示会进行全表查询,而且possible_key和key都为NULL,表示mysql没有选择索引,通常在这种查询情况下mysql表现会很差。
到目前为止,其实导致DB机器CPU飙高的罪魁祸首已经浮出水面。我们在艺人上直播发送tips的应用中,会对所有100张用户表进行查询,查询sql类似如下:
Select user_uin from user_listen_anchor_0 where anchor_uin = 446965545;
从上面的实验结果中,我们可以知道其实上面的查询sql是不会命中索引的,所以就会导致所有的查询都是全表的慢查询,这也CPU飙升到100%的原因。解决的办法就是在anchor_uin这个列上加上索引,这样DB的CPU瞬间降到2%-3%,如上面CPU曲线图的蓝色框部分。
1、索引简介
索引是mysql快速搜索的关键,mysql索引的建立对于mysql的高效运行是很重要的。我们平常所说的索引,如果没有特别说明,都是指B+树结构组织的B-tree索引(当然除了B+树这种索引外,还有哈希索引)。索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引只包含多个列。
索引类型:普通索引,唯一索引,主键索引,组合索引
2、选择合适的数据类型
mysql支持很多数据类型,选择合适的数据类型存储数据对性能有很大的影响。原则如下:
(1)越小的数据类型通常更好
(2)简单的数据类型更好
(3)尽量避免NULL,应该指定列为NOT NULL
3、建立索引的时机
一般来说,在where和join中出现的列需要建立索引,但也不完全如此,因为mysql只对<,<=,=,>,>=,BETWEEN,IN以及某些时候的LIKE才会使用索引。某些时候的LIKE才需要建立索引是因为在以通配符%和_开头作查询时,mysql不会使用索引。
4、使用索引的注意事项
(1)索引不会包含有NULL值的列
(2)使用短索引(提高查询速度,节省磁盘空间和IO操作)
(3)不使用NOT IN和<>
(4)如果索引了多列,要遵守最左前缀法则,即查询从索引的最左前列开始,并且不会跳过索引中的列
(5)索引列不应该作为表达式的一部分,即也不能在索引上使用函数
(6)不要使用类型转换
(7)order by,尽量使用index方式排序(表示mysql扫描索引本身完成排序),避免使用FileSort排序(order by满足一下情况会使用index方式排序: 1.order by语句使用索引最左前列 2.使用where子句和order by子句条件组合满足索引最左前列规则)
(8)慎用left join(left join会创建临时表)
(9)谨防where子句中的OR(where语句使用or,且没有使用覆盖索引,会进行全表扫描),尽量使用UNION代替OR
(10)善用LIMIT和覆盖索引,减少select * from ...的使用
5、索引的不足之处
(1)虽然索引大大提高了查询速度,但是也会降低更新表的速度,比如对表进行insert、update和delete操作。因为更新表时,mysql不仅要保存数据,还要保存一下索引文件。
(2)建立索引会占用磁盘空间的索引文件。一般情况下不用考虑这个问题,但是如果在一个大表上建立多种组合索引,索引文件也会膨胀很快。